
Hi, as you might know, pontifex2 aka download.o.o serves 4 major roles atm. 1. download.opensuse.org redirector for zypper repos 2. downloadcontent.opensuse.org fallback mirror 3. stage.opensuse.org rsync source server for major mirrors 4. repopusher to 6 mirrors During August, my nagios monitoring has logged at least 20+10+20+19+22+70+30+10+20+10+10 minutes of high packet loss on download.o.o - that is 241m or 4h When I captured a tcpdump during such a troublesome moment, I found that 89% of it was rsync traffic and the total traffic sent was between 2.5 and 3 GBit/s on average, with 60 different mirror IPs. We only have a 4GBit/s link there shared for all of the Nuremberg SUSE Maxtorhof stuff. That indicates that 3. and 4. above saturated the link and that contibuted to high packet loss that makes for a very poor user-experience of download.o.o users. With 60 mirrors rsyncing simultaneously at 3GBit, that leaves around 6 MByte/s for each mirror and that means, syncing just 122GB of Factory takes over 5h. [Math 122000/(3000.0/8/60)/60/60 => 5.4 ] To solve this, we should try to separate these roles so that they conflict less with each other. The first thing we should try is to move out and split stage.o.o . Ideally, the data should be transferred only once to each continent via repopusher and then other mirrors pull from these primary mirrors. Another easy improvement might be to serve download.o.o via mirrorcache from another network. This might not even need much bandwidth as it mostly serves redirects. I'd like to have Andrii's opinion on this, once he is back from vacation. As this is a major change to our download infra, I don't want to decide on that alone, so I'd appreciate your feedback if and how we should change things. Ciao Bernhard M.

Bernhard M. Wiedemann wrote:
Hi,
as you might know, pontifex2 aka download.o.o serves 4 major roles atm.
1. download.opensuse.org redirector for zypper repos 2. downloadcontent.opensuse.org fallback mirror 3. stage.opensuse.org rsync source server for major mirrors 4. repopusher to 6 mirrors
Six only because another five are waiting to be fixed by the "mirror admin" ...
During August, my nagios monitoring has logged at least 20+10+20+19+22+70+30+10+20+10+10 minutes of high packet loss on download.o.o - that is 241m or 4h
When I captured a tcpdump during such a troublesome moment, I found that 89% of it was rsync traffic and the total traffic sent was between 2.5 and 3 GBit/s on average, with 60 different mirror IPs. We only have a 4GBit/s link there shared for all of the Nuremberg SUSE Maxtorhof stuff.
That indicates that 3. and 4. above saturated the link and that contibuted to high packet loss that makes for a very poor user-experience of download.o.o users.
Yeah, that is likely true.
To solve this, we should try to separate these roles so that they conflict less with each other. The first thing we should try is to move out and split stage.o.o .
No. The first thing we should do is identify and discuss the issue. Second, I disagree with your up-front conclusion. IMHO, the issue is too much data and too little bandwidth. So I suggest we first look at: a) why is there too much data? b) why is there too little bandwidth?
Ideally, the data should be transferred only once to each continent via repopusher and then other mirrors pull from these primary mirrors.
Ideally, we would have sufficient bandwidth. If that is not forthcoming, we reduce traffic to accomodate our users as best we can. I personally think the repository push is largely useless - unless we can get it out to the mirror sites, in time.
As this is a major change to our download infra, I don't want to decide on that alone, so I'd appreciate your feedback if and how we should change things.
Again, we should identify the issue first of all. As we know, it is insufficient bandwidth. If we cannot get more bandwidth, we have to prioritise what we send where and when. I say skip the repositories push - it is persistently way behind, and despite my recent efforts to optimise it, it's not getting any better. -- Per Jessen, Zürich (19.1°C) Member, openSUSE Heroes

On 04/09/2022 23.08, Per Jessen wrote:
IMHO, the issue is too much data and too little bandwidth. So I suggest we first look at:
a) why is there too much data? b) why is there too little bandwidth?
Indeed. a) AIUI because we transfer the same big data to 60+ mirrors at the same time from this one central location. A problem that bittorrent solved by transferring between peers P2P. b) there is only a 4GBit/s link atm. Mikelis proposed to setup another dedicated 4GBit/s link just for openSUSE, but since we were already using >2.5GBit, that can only improve the situation a little. There will be a move to the Prague DC next year, that could give us up to 10GBit/s, but even with that, we should still think about improving the organization of the transfers.
Again, we should identify the issue first of all. As we know, it is insufficient bandwidth. If we cannot get more bandwidth, we have to prioritise what we send where and when.
I say skip the repositories push - it is persistently way behind, and despite my recent efforts to optimise it, it's not getting any better.
IMHO, repopush also suffers from the other 60 mirrors using up the shared bandwidth. repopush is not the problem. I think, it can even be part of the solution, because with it, we have better control over what gets pushed when. Ciao Bernhard M.
I gathered some more data points: /var/log/apache2/download.opensuse.org/2022/09/download.opensuse.org-20220904-access_log.xz contained 200 GB worth of HTTP 200 responses - counted with perl -ne 'm/ 200 (\d+) / and $s+=$1; END{print $s}' /var/log/nginx/downloadcontent/2022/09/2022-09-04-access.log-20220905.xz contained 720 GB worth of HTTP 200 and another 100 GB worth of 206 (Partial) responses for that day. /proc/net/dev showed an average of 21TB/d sent over the 6d uptime - equivalent of a continuous 2GBit/s - but of course it is not steady. I used grep -o "GET [^ ]* HTTP/1.* 200 [^ ]* " \ 2022-09-04-access.log-20220905 | sort|uniq -c|sort -n | tail -200 > most-requested-direct-downloads-size To get the list of most requested (unmirrored) files (attached) and found that a caching squid frontend could provide nice bandwidth savings for tumbleweed and update repos - but probably less than those 720 GB/d served. I still think that the main problem is the rsync traffic. You can use tcpdump -nr with the /tmp/dump*.pcap files and look for rsync port 873, which made up 89% of it. Apart from the practical tcpdump approach, there is also the math, that says, dividing 3000 MBit/s by 70 mirrors leaves only 43 MBit/s to each of them. I think, the best approach would be to find or create a few well-connected rsync mirrors that get pushed /tumbleweed and /update first and from there, the other mirrors can sync. This could increase latency of updates, because it needs 2 copies to reach most mirrors, but OTOH, the copies should happen much faster, because more total bandwidth will be available. Ciao Bernhard M.

Per Jessen wrote:
Second, I disagree with your up-front conclusion.
In my understanding it is not even about cause/conclusion , but more about 'divide and conquer' principle. I see many advantages from splitting the services between machines: starting from easiness of gathering of performance metrics, troubleshooting, salting or even dealing with accidental or planned downtime. If there are disadvantages or architecture limitations - in my understanding we should discuss them instead of trying to justify current monolithic construction or try to demand a proof that the split will solve all the problems. I kind of agree that splitting may be not enough to fix everything, but it still should bring obvious advantages and should simplify further work. Other issues (e.g. count of mirrors to push to or limited line throughput) should not block or obsolete the split. Regards, Andrii Nikitin
On 04/09/2022 20.14, Bernhard M. Wiedemann wrote:
Hi,
as you might know, pontifex2 aka download.o.o serves 4 major roles atm.
1. download.opensuse.org redirector for zypper repos 2. downloadcontent.opensuse.org fallback mirror 3. stage.opensuse.org rsync source server for major mirrors 4. repopusher to 6 mirrors
During August, my nagios monitoring has logged at least 20+10+20+19+22+70+30+10+20+10+10 minutes of high packet loss on download.o.o - that is 241m or 4h
The last download.o.o packet losses reported by my nagios were on 2022-09-13 and 2022-09-20 and each time only 10 minutes. I had created https://progress.opensuse.org/projects/opensuse-admin-wiki/wiki/Downloadcont... to relieve the host of task #2 Initially I thought, those few hundreds GB/d would not make much of an impact. Yet, it turned out that the distribution of the traffic had occasional really tall spikes up to 200 MByte/s (see attachment) Usually those spikes occurred after a new Leap 15.3 update-sle version came out when 900 users fetched that 120MB primary.xml.gz file before it reached the mirrors. https://github.com/openSUSE/open-build-service/issues/13094 could help there, but it probably won't be implemented for possibly invalid reasons. Some more testing/analysis around such partial zypper repodata transfers could help. Another way to improve these peaks would be to use some delayed publishing similar to tumbleweed, so the mirrors take that load. See pontifex2:/home/mirror/bin/publish_factory Or we just leave that as is, since downloadcontent2.o.o seems to be able to handle it fine within its traffic limits. Meanwhile the rsync traffic still sometimes reaches 3Gbit/s of our shared 4GBit/s uplink. I noticed that the excludes in repopush seem to not work. There are some largish repos that are updated often, but not requested much from mirrors. So we end up spending more traffic on rsyncing them out than would be needed to serve these files directly. I took a random sample of repos that took time to rsync: du -sm 49460 /srv/ftp/pub/opensuse/repositories/devel:/ARM:/Factory:/Contrib:/HEAD/images/ 14835 /srv/ftp/pub/opensuse/repositories/systemsmanagement:/Uyuni:/Master/images 59546 /srv/ftp/pub/opensuse/repositories/devel:/gcc:/next/ 118473 /srv/ftp/pub/opensuse/repositories/home:/Guillaume_G:/isp1760/images/ 7506 /srv/ftp/pub/opensuse/repositories/home:/johnny_law:/sle/images/ /var/log/apache2/download.opensuse.org/access_log shows only downloads for repo metadata in the 6h since log rotation. So should we push less of /repositories/ out to fewer places? The other improvement I have in mind is to find some well-connected host with 300-600 TB/month traffic and 3TB SSD that gets /tumbleweed /distribution /updates as soon as possible and to offer that as rsync source to mirror operators. This should take load off task #3 and thus leave more disk-IO and network bandwidth to the other tasks. Ciao Bernhard M.
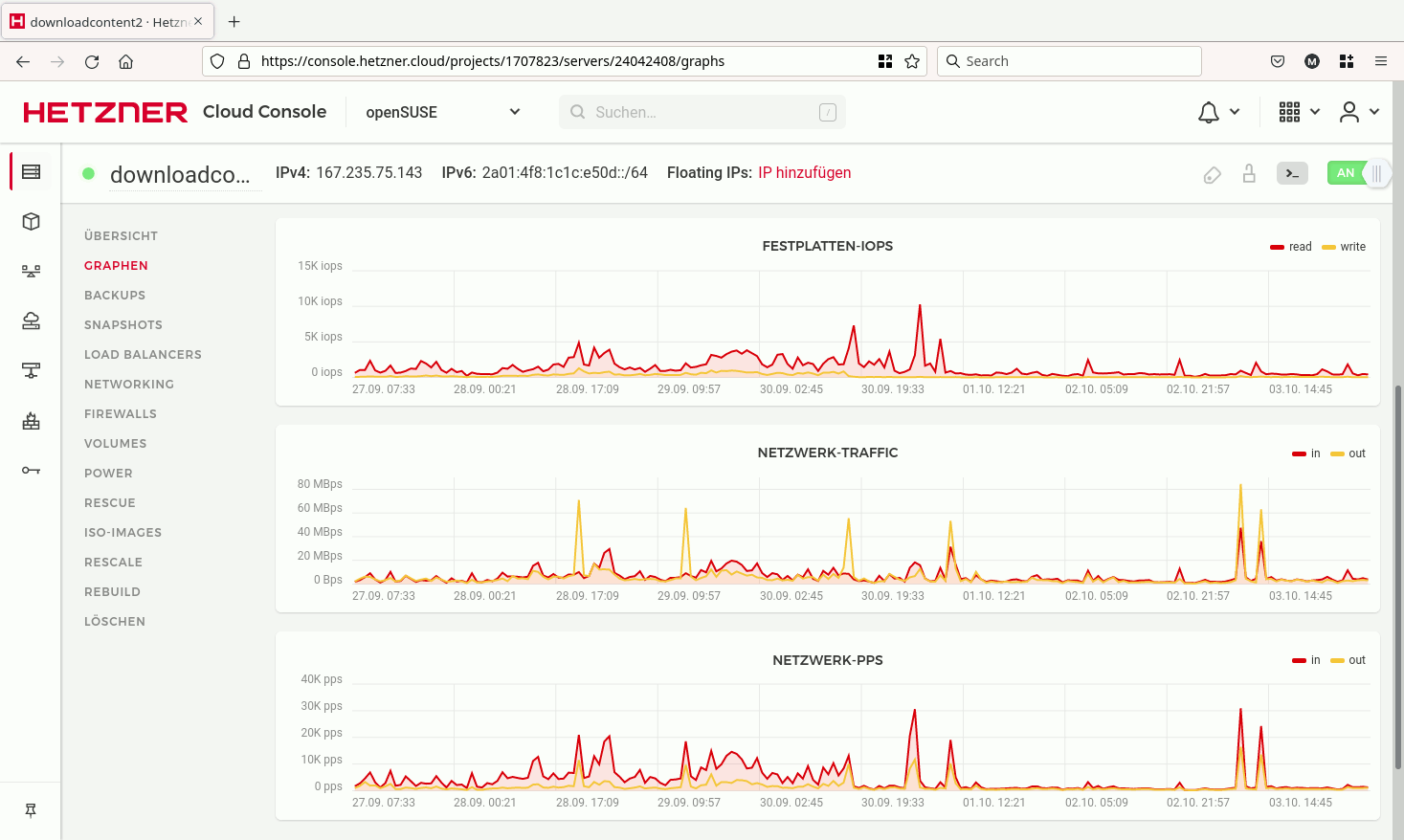{kind=link}
Bernhard M. Wiedemann wrote:
I noticed that the excludes in repopush seem to not work.
That sounds odd. I did remove from excludes from e.g. rsync.o.o, so we have a complete copy there.
There are some largish repos that are updated often, but not requested much from mirrors. So we end up spending more traffic on rsyncing them out than would be needed to serve these files directly.
Yes, I'm sure that is correct. I have not gone to the trouble of analysing it in that detail.
So should we push less of /repositories/ out to fewer places?
We are only pushing /repositories/ to six mirrors anyway, two of which are our own. I see no real problem in pushing less, it just needs to be managed.
The other improvement I have in mind is to find some well-connected host with 300-600 TB/month traffic and 3TB SSD that gets /tumbleweed /distribution /updates as soon as possible and to offer that as rsync source to mirror operators. This should take load off task #3 and thus leave more disk-IO and network bandwidth to the other tasks.
In the September meeting, I think it was mentioned that our uplink is going to get upgraded to 10Gbit ? -- Per Jessen, Zürich (18.6°C) Member, openSUSE Heroes (2016 - present) We're hiring - https://en.opensuse.org/openSUSE:Heroes
On 05/10/2022 15.41, Per Jessen wrote:
In the September meeting, I think it was mentioned that our uplink is going to get upgraded to 10Gbit ?
That is planned for 2023-05 with the new datacenter so still ~8 months away. It should indeed solve the trouble, if disk-IO can keep up. Meanwhile, some fixes to how we rsync brought some improvement. I only see half the usual disk-IO and network-IO atm. Around 1Gbit/s Ciao Bernhard M.
participants (4)
-
 Andrii Nikitin
Andrii Nikitin -
 Bernhard M. Wiedemann
Bernhard M. Wiedemann -
 Bernhard M. Wiedemann
Bernhard M. Wiedemann -
 Per Jessen
Per Jessen